Gemma 4: Our most intelligent open models to date, purpose-built for advanced reasoning and agentic workflows.
( 17
min )
Gemma 4: Our most intelligent open models to date, purpose-built for advanced reasoning and agentic workflows.
( 17
min )
 Google is introducing two new inference tiers to the Gemini API, Flex and Priority,
to balance cost and latency.
( 14
min )
Google is introducing two new inference tiers to the Gemini API, Flex and Priority,
to balance cost and latency.
( 14
min )
 New AI capabilities are coming to Google Vids, powered by Lyria 3 and Veo 3.1, like high-quality video generation at no cost and more.
( 16
min )
New AI capabilities are coming to Google Vids, powered by Lyria 3 and Veo 3.1, like high-quality video generation at no cost and more.
( 16
min )
 Despite their sophisticated general-purpose capabilities, Large Language Models (LLMs) often fail to align with diverse individual preferences because standard post-training methods, like Reinforcement Learning with Human Feedback (RLHF), optimize for a single, global objective. While Group Relative Policy Optimization (GRPO) is a widely adopted on-policy reinforcement learning framework, its group-based normalization implicitly assumes that all samples are exchangeable, inheriting this limitation in personalized settings. This assumption conflates distinct user reward distributions and…
( 3
min )
Despite their sophisticated general-purpose capabilities, Large Language Models (LLMs) often fail to align with diverse individual preferences because standard post-training methods, like Reinforcement Learning with Human Feedback (RLHF), optimize for a single, global objective. While Group Relative Policy Optimization (GRPO) is a widely adopted on-policy reinforcement learning framework, its group-based normalization implicitly assumes that all samples are exchangeable, inheriting this limitation in personalized settings. This assumption conflates distinct user reward distributions and…
( 3
min )
 Google partnered with the Brazilian government on a satellite imagery map to help protect the country’s forests.
( 14
min )
Google partnered with the Brazilian government on a satellite imagery map to help protect the country’s forests.
( 14
min )
 Here are Google’s latest AI updates from March 2026
( 19
min )
Here are Google’s latest AI updates from March 2026
( 19
min )
 Veo 3.1 Lite is now available in paid preview through the Gemini API and for testing in Google AI Studio.
( 14
min )
We introduce ProText, a dataset for measuring gendering and misgendering in stylistically diverse long-form English texts. ProText spans three dimensions: Theme nouns (names, occupations, titles, kinship terms), Theme category (stereotypically male, stereotypically female, gender-neutral/non-gendered), and Pronoun category (masculine, feminine, gender-neutral, none). The dataset is designed to probe (mis)gendering in text transformations such as summarization and rewrites using state-of-the-art Large Language Models, extending beyond traditional pronoun resolution benchmarks and beyond the…
( 2
min )
Synthetic data can improve generalization when real data is scarce, but excessive reliance may introduce distributional mismatches that degrade performance. In this paper, we present a learning-theoretic framework to quantify the trade-off between synthetic and real data. Our approach leverages algorithmic stability to derive generalization error bounds, characterizing the optimal synthetic-to-real data ratio that minimizes expected test error as a function of the Wasserstein distance between the real and synthetic distributions. We motivate our framework in the setting of kernel ridge…
( 3
min )
State Space Models (SSMs) have become the leading alternative to Transformers for sequence modeling. Their primary advantage is efficiency in long-context and long-form generation, enabled by fixed-size memory and linear scaling of computational complexity. We begin this work by showing a simple theoretical result stating that SSMs cannot accurately solve any “truly long-form” generation problem (in a sense we formally define), undermining their main competitive advantage. However, we show that this limitation can be mitigated by allowing SSMs interactive access to external tools. In fact, we…
( 3
min )
It is challenging to generate the code for a complete user interface using a Large Language Model (LLM). User interfaces are complex and their implementations often consist of multiple, inter-related files that together specify the contents of each screen, the navigation flows between the screens, and the data model used throughout the application. It is challenging to craft a single prompt for an LLM that contains enough detail to generate a complete user interface, and even then the result is frequently a single large and difficult to understand file that contains all of the generated…
( 3
min )
Veo 3.1 Lite is now available in paid preview through the Gemini API and for testing in Google AI Studio.
( 14
min )
We introduce ProText, a dataset for measuring gendering and misgendering in stylistically diverse long-form English texts. ProText spans three dimensions: Theme nouns (names, occupations, titles, kinship terms), Theme category (stereotypically male, stereotypically female, gender-neutral/non-gendered), and Pronoun category (masculine, feminine, gender-neutral, none). The dataset is designed to probe (mis)gendering in text transformations such as summarization and rewrites using state-of-the-art Large Language Models, extending beyond traditional pronoun resolution benchmarks and beyond the…
( 2
min )
Synthetic data can improve generalization when real data is scarce, but excessive reliance may introduce distributional mismatches that degrade performance. In this paper, we present a learning-theoretic framework to quantify the trade-off between synthetic and real data. Our approach leverages algorithmic stability to derive generalization error bounds, characterizing the optimal synthetic-to-real data ratio that minimizes expected test error as a function of the Wasserstein distance between the real and synthetic distributions. We motivate our framework in the setting of kernel ridge…
( 3
min )
State Space Models (SSMs) have become the leading alternative to Transformers for sequence modeling. Their primary advantage is efficiency in long-context and long-form generation, enabled by fixed-size memory and linear scaling of computational complexity. We begin this work by showing a simple theoretical result stating that SSMs cannot accurately solve any “truly long-form” generation problem (in a sense we formally define), undermining their main competitive advantage. However, we show that this limitation can be mitigated by allowing SSMs interactive access to external tools. In fact, we…
( 3
min )
It is challenging to generate the code for a complete user interface using a Large Language Model (LLM). User interfaces are complex and their implementations often consist of multiple, inter-related files that together specify the contents of each screen, the navigation flows between the screens, and the data model used throughout the application. It is challenging to craft a single prompt for an LLM that contains enough detail to generate a complete user interface, and even then the result is frequently a single large and difficult to understand file that contains all of the generated…
( 3
min )
 Google Translate’s Live translate with headphones is officially arriving on iOS! And we're expanding the capability for both iOS and Android users to even more countries…
( 15
min )
Google Translate’s Live translate with headphones is officially arriving on iOS! And we're expanding the capability for both iOS and Android users to even more countries…
( 15
min )
 Gemini 3.1 Flash Live is now available across Google products.
( 18
min )
Gemini 3.1 Flash Live is now available across Google products.
( 18
min )
 We’re expanding Search Live globally, to all languages and locations where AI Mode is available.
( 14
min )
Our latest voice model has improved precision and lower latency to make voice interactions more fluid, natural and precise.
( 18
min )
While scaling laws for Large Language Models (LLMs) traditionally focus on proxy metrics like pretraining loss, predicting downstream task performance has been considered unreliable. This paper challenges that view by proposing a direct framework to model the scaling of benchmark performance from the training budget. We find that for a fixed token-to-parameter ratio, a simple power law can accurately describe the scaling behavior of log accuracy on multiple popular downstream tasks. Our results show that the direct approach extrapolates better than the previously proposed two-stage procedure…
( 3
min )
We’re expanding Search Live globally, to all languages and locations where AI Mode is available.
( 14
min )
Our latest voice model has improved precision and lower latency to make voice interactions more fluid, natural and precise.
( 18
min )
While scaling laws for Large Language Models (LLMs) traditionally focus on proxy metrics like pretraining loss, predicting downstream task performance has been considered unreliable. This paper challenges that view by proposing a direct framework to model the scaling of benchmark performance from the training budget. We find that for a fixed token-to-parameter ratio, a simple power law can accurately describe the scaling behavior of log accuracy on multiple popular downstream tasks. Our results show that the direct approach extrapolates better than the previously proposed two-stage procedure…
( 3
min )
 Run cloud agents in your own infrastructure
( 16
min )
Run cloud agents in your own infrastructure
( 16
min )
 Google DeepMind researches AI's harmful manipulation risks across areas like finance and health, leading to new safety measures.
( 7
min )
Google DeepMind researches AI's harmful manipulation risks across areas like finance and health, leading to new safety measures.
( 7
min )
 Introducing Lyria 3 Pro, which unlocks longer tracks with structural awareness. We’re also bringing Lyria to more Google products and surfaces.
( 15
min )
Introducing Lyria 3 Pro, which unlocks longer tracks with structural awareness. We’re also bringing Lyria to more Google products and surfaces.
( 15
min )
 Lyria 3 is now available in paid preview through the Gemini API and for testing in Google AI Studio.
( 16
min )
We are bringing Lyria 3 to the tools where professionals work and create every day.
( 15
min )
This paper was accepted at the Workshop on Latent & Implicit Thinking – Going Beyond CoT Reasoning 2026 at ICLR.
Autoregressive language models trained with next-token prediction generate text by sampling one discrete token at a time. Although very scalable, this objective forces the model to commit at every step, preventing it from exploring or reflecting upon multiple plausible continuations. Furthermore, the compute allocation across tokens is uniform; every token is formed based on a single forward-pass, potentially limiting the model’s expressiveness in cases where difficult tokens…
( 3
min )
Lyria 3 is now available in paid preview through the Gemini API and for testing in Google AI Studio.
( 16
min )
We are bringing Lyria 3 to the tools where professionals work and create every day.
( 15
min )
This paper was accepted at the Workshop on Latent & Implicit Thinking – Going Beyond CoT Reasoning 2026 at ICLR.
Autoregressive language models trained with next-token prediction generate text by sampling one discrete token at a time. Although very scalable, this objective forces the model to commit at every step, preventing it from exploring or reflecting upon multiple plausible continuations. Furthermore, the compute allocation across tokens is uniform; every token is formed based on a single forward-pass, potentially limiting the model’s expressiveness in cases where difficult tokens…
( 3
min )
 Improving Composer through real-time RL
( 11
min )
Improving Composer through real-time RL
( 11
min )
 Mar 25, 2026
( 3
min )
Mar 25, 2026
( 3
min )
 Improving Composer through real-time RL
( 46
min )
Improving Composer through real-time RL
( 46
min )
 Improving Composer through real-time RL
( 8
min )
Improving Composer through real-time RL
( 8
min )
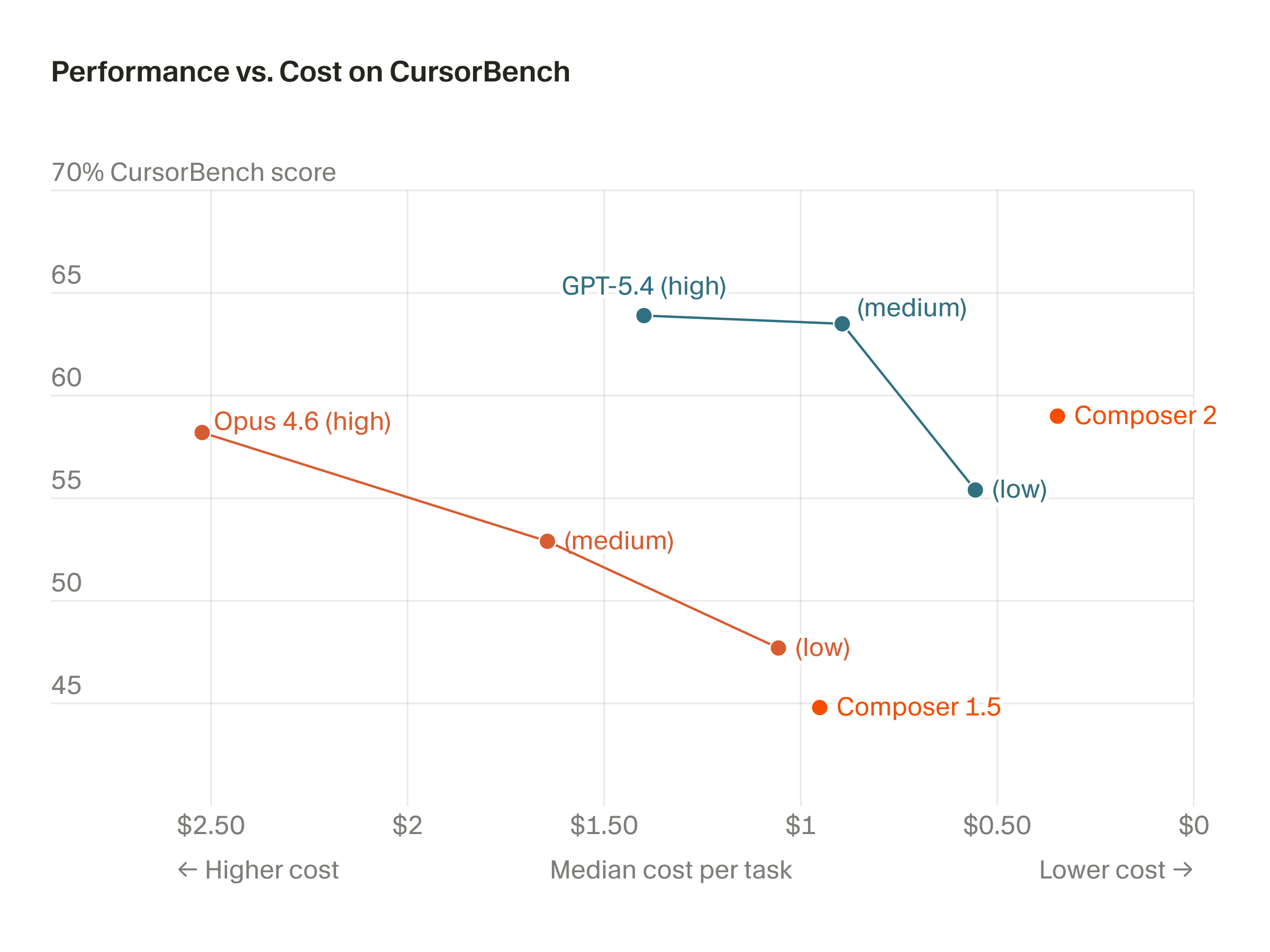 Mar 19, 2026
( 3
min )
Mar 19, 2026
( 3
min )
 Over 1,000 Money Forward employees now use Cursor every day.
( 29
min )
Over 1,000 Money Forward employees now use Cursor every day.
( 29
min )
 We’re introducing a framework to measure progress toward AGI, and launching a Kaggle hackathon to build the relevant evaluations.
( 15
min )
We’re introducing a framework to measure progress toward AGI, and launching a Kaggle hackathon to build the relevant evaluations.
( 15
min )
 We're expanding Personal Intelligence across AI Mode in Search, the Gemini app and Gemini in Chrome.
( 16
min )
We're expanding Personal Intelligence across AI Mode in Search, the Gemini app and Gemini in Chrome.
( 16
min )
 Google is making new investments, building new tools and developing code security to improve open source security.
( 14
min )
Google is making new investments, building new tools and developing code security to improve open source security.
( 14
min )
 Improving Composer through real-time RL
( 20
min )
Improving Composer through real-time RL
( 20
min )
 A new Google AI initiative aims to improve heart health outcomes for people living in remote Australian communities.
( 15
min )
A new Google AI initiative aims to improve heart health outcomes for people living in remote Australian communities.
( 15
min )
 Improving Composer through real-time RL
( 15
min )
Improving Composer through real-time RL
( 15
min )
 Improving Composer through real-time RL
( 8
min )
Improving Composer through real-time RL
( 8
min )
 Mar 11, 2026
( 3
min )
Mar 11, 2026
( 3
min )
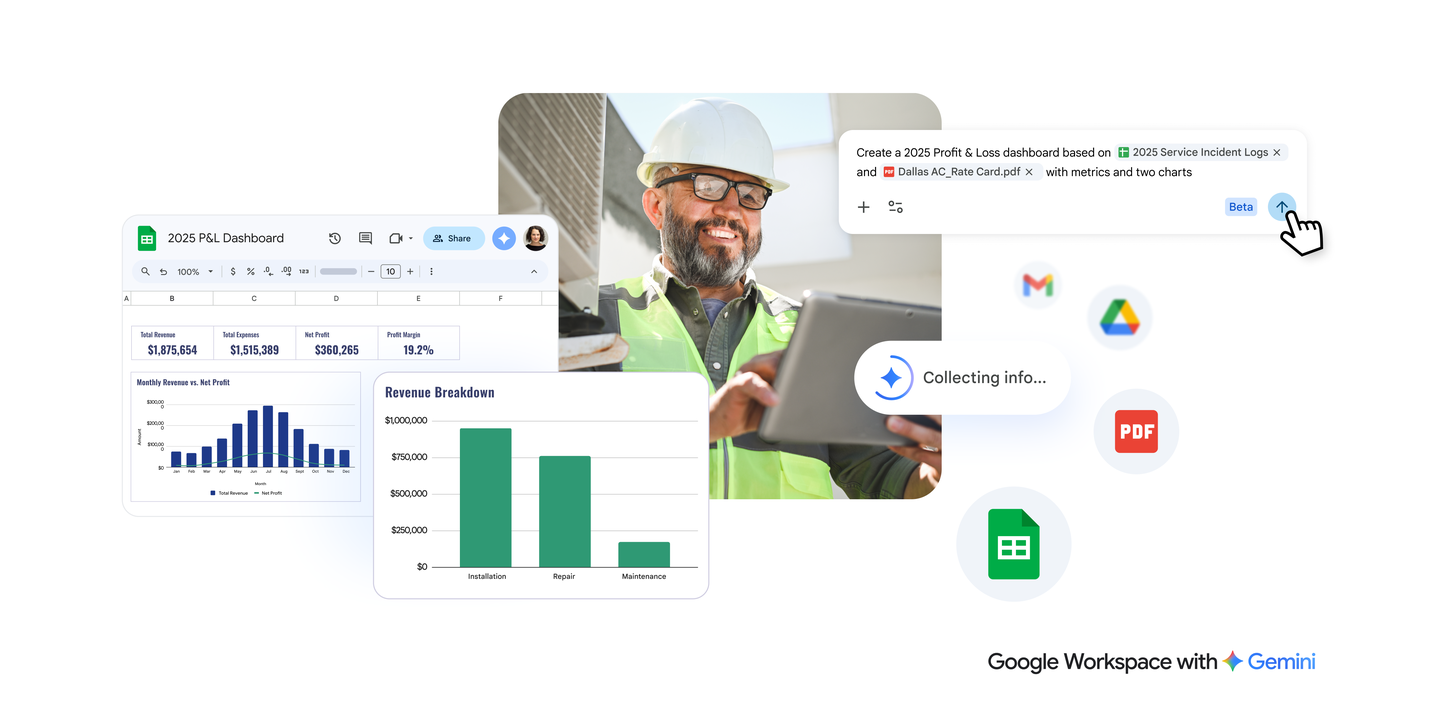 Today we announced new beta features for Gemini in Sheets to help you create, organize and edit entire sheets, from basic tasks to complex data analysis — just describe …
( 14
min )
Today we announced new beta features for Gemini in Sheets to help you create, organize and edit entire sheets, from basic tasks to complex data analysis — just describe …
( 14
min )
 Ten years since AlphaGo, we explore how it is catalyzing scientific discovery and paving a path to AGI.
( 9
min )
Ten years since AlphaGo, we explore how it is catalyzing scientific discovery and paving a path to AGI.
( 9
min )
 An overview of SpeciesNet, our open-source AI model that is helping people around the world protect and conserve wildlife.
( 17
min )
An overview of SpeciesNet, our open-source AI model that is helping people around the world protect and conserve wildlife.
( 17
min )
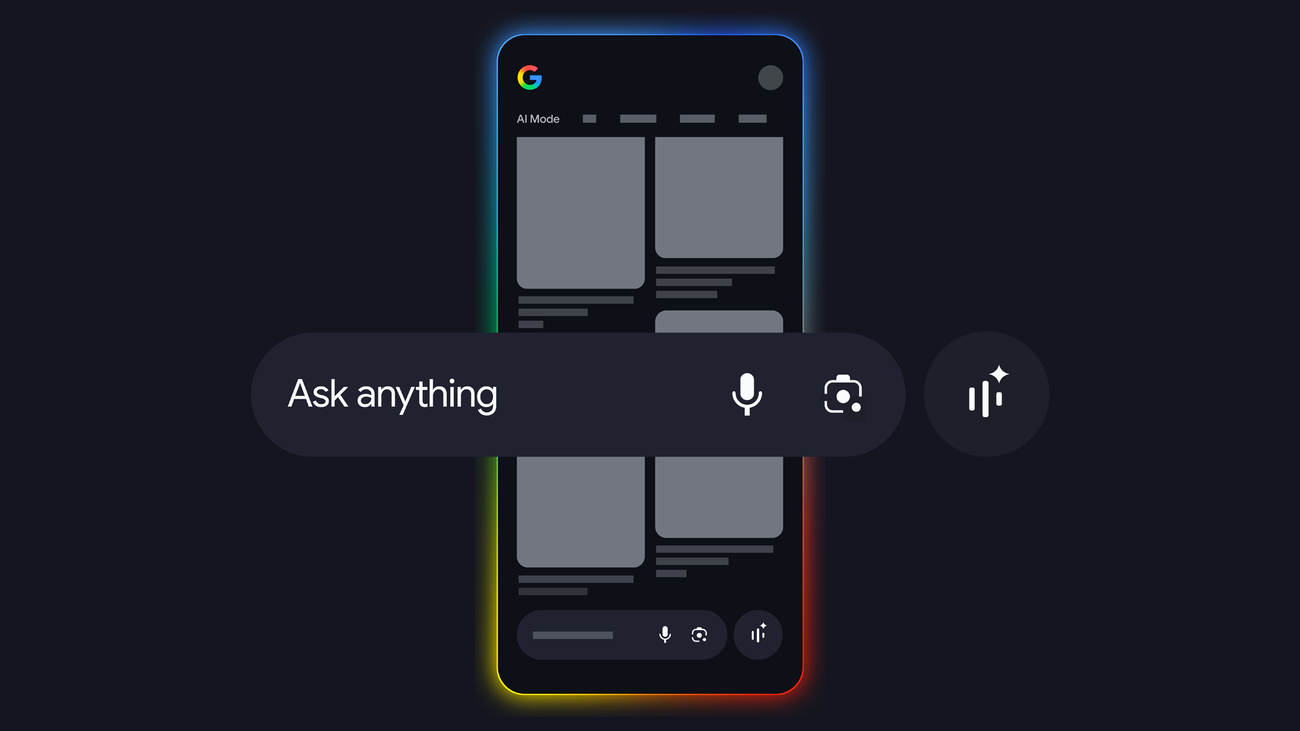 Learn more about AI Mode in Search’s query fan-out method for visual search.
( 16
min )
Learn more about AI Mode in Search’s query fan-out method for visual search.
( 16
min )
 Here are Google’s latest AI updates from February 2026
( 17
min )
Here are Google’s latest AI updates from February 2026
( 17
min )